全国计算机等级考试Python模拟卷1
1.单选题
35.下面代码的输出结果是
s =["seashell", "gold", "pink", "brown", "purple", "tomato"]
print(s[1:4:2])
A ['gold', 'brown']
B ['gold', 'pink', 'brown']
c ['gold', 'pink']
D ['gold', 'pink', 'brown', 'purple', 'tomato']
2.编程题
1.仅使用 Python 基本语法,即不使用任何模块,编写 Python 程序计算下列数学表达式的结果并输出,小数点后保留3位。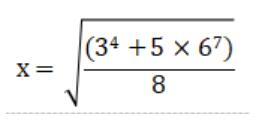
输出结果小数点后保留 3 位
2.以中国共产党第十九次全国代表大会报告中一句话作为字符串变量 s,完善 Python 程序,分别用 Python 内置函数及 jieba 库中已有函数计算字符串 s 的中文字符个数及中文词语个数。注意,中文字符包含中文标点符号。(提交的代码应包括题目中给出的部分)
import jieba
s = "中国特色社会主义进入新时代,我国社会主要矛盾已经转化为人民日益增长的美好生活需要和不平衡不充分的发展之间的矛盾。"
n = ____①____
m = ____②____
print("中文字符数为{},中文词语数为{}。".format(n, m))
输出字符串 s 的中文字符个数及中文词语个数
3.
0x4DC0 是一个十六进制数,它对应的 Unicode 编码是中国古老的《易经》六十四卦的第一卦,请输出第 51 卦(震卦)对应的 Unicode 编码的二进制、十进制、八进制和十六进制格式。
print("二进制{____①____}、十进制{____②____}、八进制{____③____}、十六进制{____④____}".format(____⑤____))
4.
使用 turtle 库的 turtle.fd() 函数和 turtle.seth() 函数绘制一个边长为 200 的正方形,效果如下图所示。请结合格式框架,补充横线处代码。
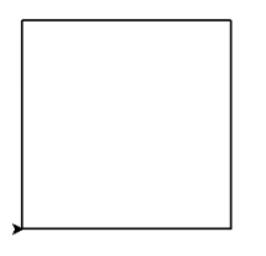
import turtle
d = 0
for i in range(____①____):
turtle.fd(____②____)
d = ____③____
turtle.seth(d)
5.
列表 ls 中存储了我国 39 所 985 高校所对应的学校类型,请以这个列表为数据变量,完善 Python 代码,统计输出各类型的数量。
ls = ["综合", "理工", "综合", "综合", "综合", "综合", "综合", "综合", "综合", "综合",\
"师范", "理工", "综合", "理工", "综合", "综合", "综合", "综合", "综合","理工",\
"理工", "理工", "理工", "师范", "综合", "农林", "理工", "综合", "理工", "理工", \
"理工", "综合", "理工", "综合", "综合", "理工", "农林", "民族", "军事"]
按 ls 中默认顺序输出
综合:1
理工:2
师范:3
农林:4
民族:5
军事:6
6.
《天龙八部》是著名作家金庸的代表作之一,历时4年创作完成。该作品气势磅礴,人物众多,非常经典。这里给出一个《天龙八部》的网络版本,文件名为“天龙八部-网络版.txt”。
问题1:请编写程序,对这个《天龙八部》文本中出现的汉字和标点符号进行统计,字符与出现次数之间用冒号:分隔,输出保存到“天龙八部-汉字统计.txt”文件中,该文件要求采用 CSV 格式存储,参考格式如下(注意,不统计空格和回车字符):
天:100, 龙:110, 八:109, 部:10
(略)
问题2:请编写程序,对《天龙八部》文本中出现的中文词语进行统计,采用 jieba 库分词,词语与出现次数之间用冒号:分隔,输出保存到“天龙八部-词语统计.txt”文件中。参考格式如下(注意,不统计任何标点符号):
天龙:100, 八部:10
(略)